I enjoy writing fiction and talking with fanfiction authors. For fun, and to satisfy my curiosity, I performed 2 analyses on fictions from fanfiction.net (FFN), obtained from the file "fanfic-131.7z" from this archive. The first analysis uses Languagetool, a spelling and grammar checker, to sort pokemon stories in order of most to least "correct". The second examines sentiment of all stories with Vader to see how the results match up with my expectations. My hope would have been to use these metrics for automated curation, but the results suggest that Languagetool may not be appropriate for assessing story quality.
Some "fanfictions" that made it into the archive consisted of copy-pasted spam, garbled computer logs or html, or similarly irrelevant content. A couple of these stories were megabytes in size and would have taken a long time to analyze. I identified such stories by compressing them each into a zip file and comparing the compressed filesize to the original filesize. If the compressed filesize was less than 10% of the original filesize, the story was removed. This works because redundant text compresses more efficiently. These redundant stories were also manually reviewed to ensure they were fit for removal.
The archive also contained some fanfictions with duplicate FFN story ids (usually the same story with a modified title.) These duplicate copies were excluded.
Stories on FFN are labeled with their language. These labels were used to exclude non-english fics.
I used R (R Core Team, 2021) for some data analysis and used the ggplot2 (Wickham, 2016) and plotly (Sievert, 2020) R packages to produce graphs. I used NLTK to tokenize sentences (Bird et al., 2009).
I created a script which detects spelling and grammatical errors in pokemon fanfics and assigns them a score based on the number of mistakes per word (lower is better). The script inserts this score, the errors themselves, and information about the fanfictions into a database.
I used Languagetool to detect errors. I told the spellchecker not to flag any words from this thread as misspelled. To account for pluralizing pokemon with an "s" (e.g. "Arcanines"), I also told the spellchecker to accept any pokemon name in that list followed by an "s". So as not to penalize stories containing unconventional character or location names, I did not include typo suggestions for words starting with a capital letter, though I recorded these suggestions in the database. To speed up processing time, only the first 2000 words of the story were considered, including chapter titles.
This approach is, at best, a very rough way of assessing fic quality, and disadvantages stories that deliberately employ unconventional formatting, eye dialect, invented words, or informal language. Additionally, since the list of pokemon terms I told the spellchecker to ignore is outdated, stories are effectively penalized for employing more recent pokemon terms unless those terms are capitalized. The fact that all typo errors for words starting with a capital letter are ignored is also bound to lead to some false negatives (e.g. if a word is misspelled at the beginning of a sentence or if all-caps is abused); however, test runs suggest that this harm is outweighed by the large number of false positives encountered otherwise.
Because only the first 2000 words are considered, the score accounts poorly for gradual improvement (or deterioration, for that matter) over the course of longer stories. Also problematic is that some stories contain author's notes at the beginning or end of chapters, which probably shouldn't be used to judge the story's quality. It is possible most notes could have been avoided by excluding a certain number of words/sentences/paragraphs after the start and before the end of each chapter. Excluding dialogue from the analysis could perhaps also improve results. I imagine dialogue deliberately deviates from standard spelling and grammar more frequently than narration.
Finally, Languagetool's style suggestions are not necessarily objective or based on a specific style guide. For example, the tool marks repetition (three sentences starting with the same word) as a mistake even though it may be used for literary effect.
As you might expect, some extremely short "works" received perfect scores despite dubious merit. In fact, none of the perfect-scoring stories were long enough to reach the 2000 word limit. The highest-ranking story to reach the limit was A Mt Silver Legendary Mystery, which is still quite flawed prose-wise. I suspect the highest-scoring stories were from authors who themselves used Languagetool (it’s built into certain word processors) and took its suggestions seriously.
On the opposite end of the spectrum, the stories with the poorest scores were generally comically bad/borderline unreadable, so I can't conclude that there is no correlation between score and quality.
Scoring fanfics based on mistakes per word is effective if you want to find something to laugh at. If you want to find well-written fanfic, I would suggest sorting by favorites or some equivalent instead.
After a project involving sentiment analysis on tweets with Vader (Hutto & Gilbert, 2014), I decided to include it in my fiction analysis.
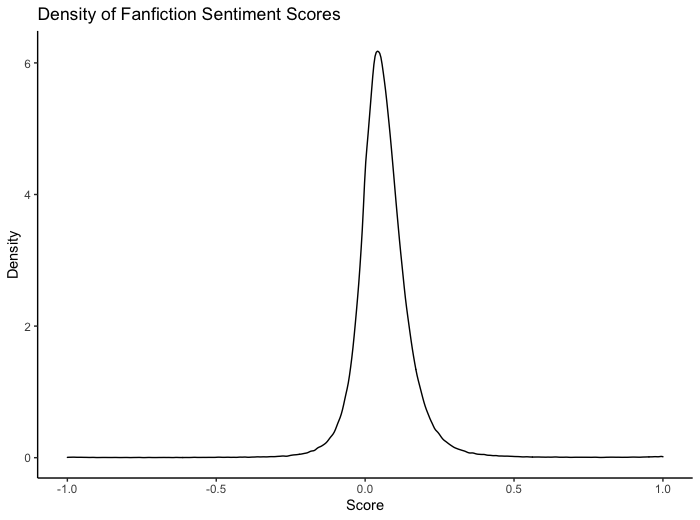
I modified the script in part 1 and ran it on all stories with no word limit. This was feasible because Vader's sentiment analysis runs far faster than Languagetool's spelling and grammar checks. As Vader's documentation suggests, I broke each story into separate sentences using NLTK's sent_tokenize function, calculated the compound score for each sentence, then recorded the average of those scores. The resulting value is between -1 and 1, with lower values indicating more negative sentiment and higher values indicating more positive sentiment. Values between -0.05 and 0.05 are considered neutral. The sentence tokenizer I used seems only to consider punctuation, which means that poems (which tend to end sentences on a linebreak with no punctuation) were often analyzed as though they contained a single long sentence. The sentiment of poems, therefore, may appear more erratic and less accurate than it really is. The same issue applies for stories which use or omit punctuation in unusual places.
On FFN, stories may be tagged with 0, 1, or 2 genres. When I group stories by genre, I consider a story with 2 genres as falling under both. Such stories are effectively counted twice—once per each genre. Stories with 0 genres were assigned a genre of "\N". I wanted to handle stories belonging to 2 categories (fandoms) the same way, but this was not possible because of how stories were labeled. If a story belongs to more than one category, the categories are separated by a comma. However, some category names also contain commas. It is difficult to write a parser that knows that a label like "Law and Order, Chicago PD" signifies a crossover between the Law and Order and Chicago PD fandoms, as opposed to signifying a single fandom literally called "Law and Order, Chicago PD" (even a human might have trouble). Therefore, I considered each unique crossover to be its own category.
Sentiment scores are normally distributed.
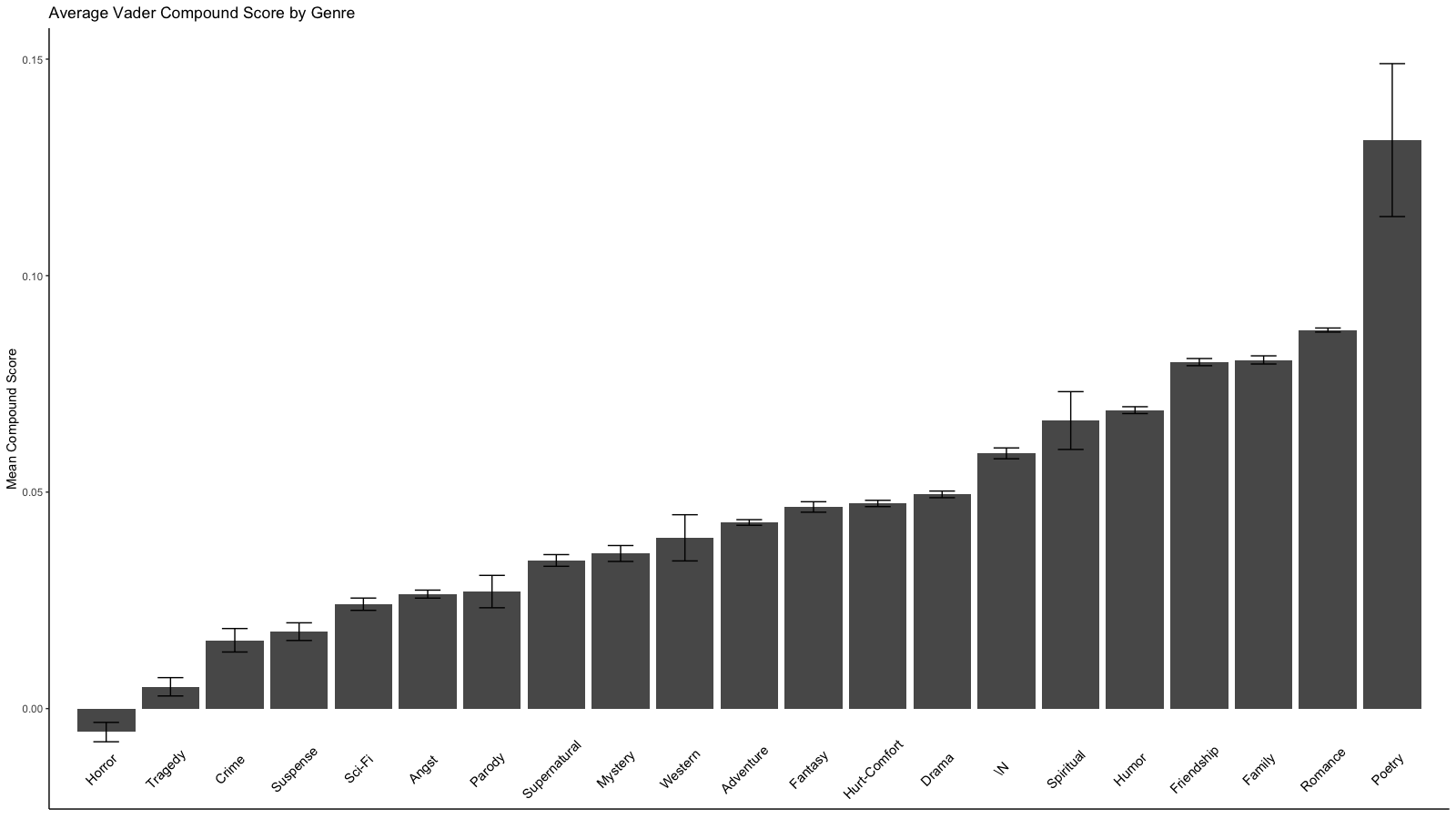
Here is an interactive graph of fanfiction mean sentiment by genre. Hover over a bar to view more details. (If you are on mobile, tapping should do the same thing.) The error bars represent the upper and lower bounds of the mean's 95% confidence interval. A static version of the graph is also available.
The range of mean sentiment is 0.13672274 with a standard deviation of 0.0316314. Because of aforementioned quirks with poetry, I somewhat doubt the accuracy of the genre's mean. That aside, the results are consistent with what one would expect—Romance, Family, and Friendship have the most positive sentiment, while Horror, Tragedy, and Crime have the most negative sentiment. The standard deviation of each genre ranges from 0.08061506 to 0.48377285 with a median of 0.08873508—given that the range of the averages is only 0.13672274, this indicates substantial variability within each genre. It is worth noting that the sentiment averages are all greater than 0, excepting Horror's.
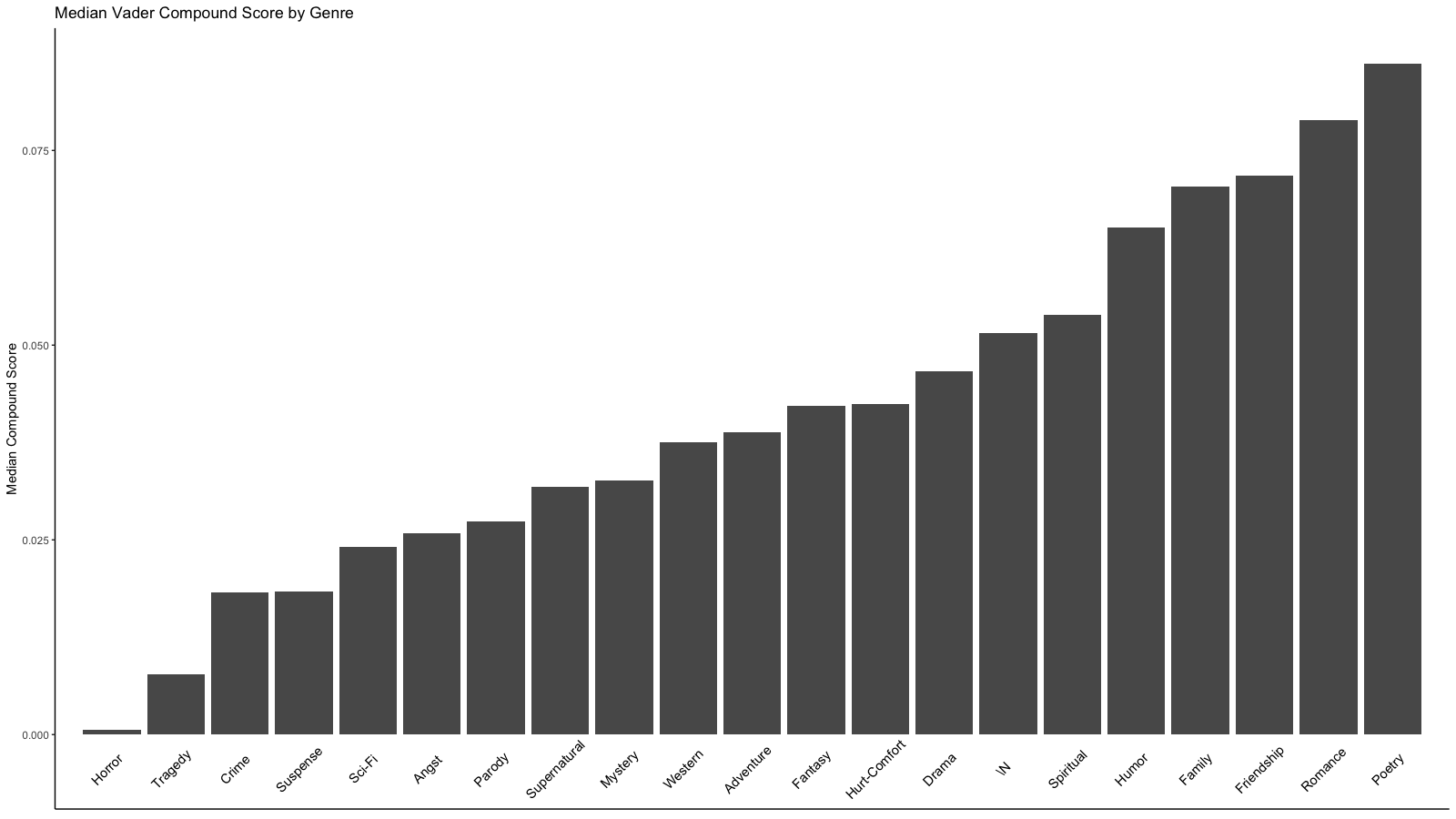
If one considers the median instead of the mean, the results are very similar. I will link a graph for those interested. That the sorted order of medians is so similar to the sorted order of means makes me think that the means are not severely impacted by outliers.
Below is an interactive graph of fanfiction mean sentiment by category. The error bars represent the upper and lower bounds of the mean's 95% confidence interval. Only categories containing 385 stories (the sample size required for a 95% confidence level) or more were included.
The range of sentiment is 0.1203968 with a standard deviation of 0.02315306. Because a category usually contains fewer fics than a genre, the confidence intervals are much wider. Nonetheless, some genres significantly differ. The four least positive categories—Batman, Resident Evil, Warcraft, and Fallout—are consistent with my intuition. It seems surprising that Danny Phantom, a cartoon aimed at a young audience, would follow behind them, but the few fans of the show I talked to have told me they do not find the result surprising. I cannot say much about the more positive categories, as I am not familiar with them. Once again, graphing the median produces similar results.
Curation with Languagetool was not very fruitful. It would be interesting to see if different writing checkers, particularly those that are not already integrated into word processors, would perform better. However, I have not found any others that are open source or that can be used from the command line.
I would tentatively say Vader's sentiment scoring aligns with human intuition. However, compared to tweets, fictional writing receives very neutral scores. I suspect this is because stories are generally longer, and when more sentences are considered, it is likely that extreme ones will be balanced out by neutral ones or ones with opposite sentiment. This supposition is consistent with poetry's highly variable scores; poetry is generally much shorter than other fanfiction. I also imagine fiction generally contains a greater quantity of neutral descriptions compared to social media posts ("He walked to the car", "She tapped her foot"). I am unsure what to make of the fact that almost all genres and categories score above zero on average, however. It would be interesting to see if this phenomenon occurs for longer nonfiction pieces like news articles or blogposts.
This study is limited by the lack of a "true" sentiment to compare Vader's scores against. A future study could assign people stories or excerpts of stories to score manually, then compare those scores with Vader's.
Bird, Steven, Edward Loper and Ewan Klein (2009), Natural Language Processing with Python. O'Reilly Media Inc.
C. Sievert. Interactive Web-Based Data Visualization with R, plotly, and shiny. Chapman and Hall/CRC Florida, 2020.
Hutto, C.J. & Gilbert, E.E. (2014). VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. Eighth International Conference on Weblogs and Social Media (ICWSM-14). Ann Arbor, MI, June 2014.
H. Wickham. ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York, 2016.
R Core Team (2021). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. URL https://www.R-project.org/.
{kind=link}
{kind=link}